
python吧 关注:473,452贴子:1,964,338

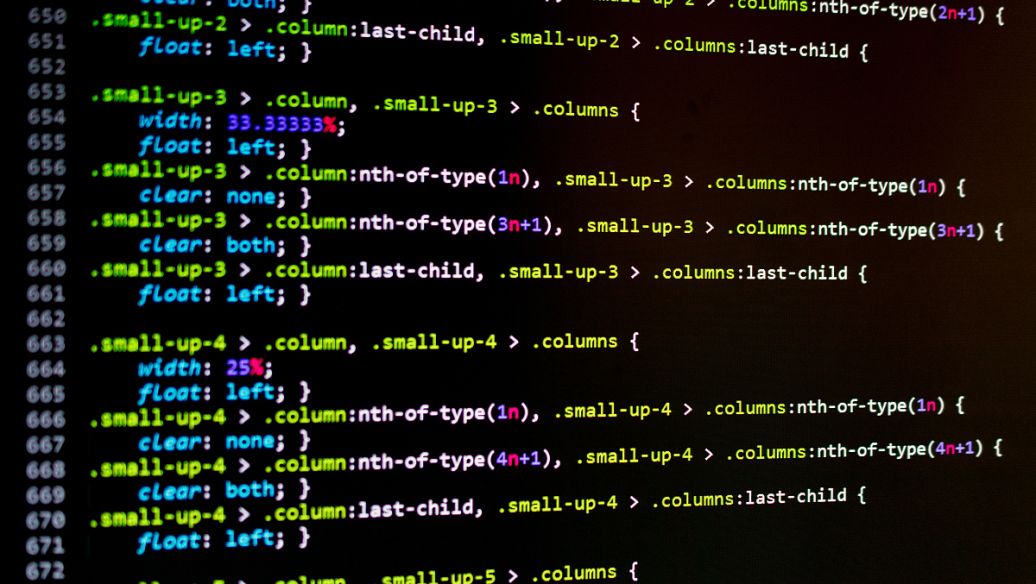








import pyttsx3
from playsound import playsound
import pyaudio
import vosk
import json
# 初始化语音识别和语音合成
engine = pyttsx3.init()
try:
model_path = r"C:\Users\yue\Desktop\vosk-model-small-cn-0.22"
model = vosk.Model(model_path)
except Exception as e:
print(f"模型加载错误: {str(e)}")
exit(1)
recognizer = vosk.KaldiRecognizer(model, 16000)
p = pyaudio.PyAudio()
try:
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=8000)
stream.start_stream()
except Exception as e:
print(f"音频流打开错误: {str(e)}")
p.terminate()
exit(1)
def recognize_speech_from_mic():
# 使用麦克风作为源来识别语音
print("请说话...")
buffer = b""
while True:
try:
data = stream.read(4000)
if len(data) == 0:
break
buffer += data
while len(buffer) > 4000:
if recognizer.AcceptWaveform(buffer[:4000]):
result = recognizer.Result()
try:
text = json.loads(result)["text"]
print(f"你说: {text}")
return text
except 网页链接 as e:
print(f"JSON解析错误: {str(e)}")
buffer = buffer[4000:]
except Exception as e:
print(f"语音识别错误: {str(e)}")
while buffer:
if len(buffer) > 4000:
if recognizer.AcceptWaveform(buffer[:4000]):
result = recognizer.Result()
try:
text = json.loads(result)["text"]
print(f"你说: {text}")
return text
except 网页链接 as e:
print(f"JSON解析错误: {str(e)}")
buffer = buffer[4000:]
else:
if recognizer.AcceptWaveform(buffer):
result = recognizer.FinalResult()

from playsound import playsound
import pyaudio
import vosk
import json
# 初始化语音识别和语音合成
engine = pyttsx3.init()
try:
model_path = r"C:\Users\yue\Desktop\vosk-model-small-cn-0.22"
model = vosk.Model(model_path)
except Exception as e:
print(f"模型加载错误: {str(e)}")
exit(1)
recognizer = vosk.KaldiRecognizer(model, 16000)
p = pyaudio.PyAudio()
try:
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=8000)
stream.start_stream()
except Exception as e:
print(f"音频流打开错误: {str(e)}")
p.terminate()
exit(1)
def recognize_speech_from_mic():
# 使用麦克风作为源来识别语音
print("请说话...")
buffer = b""
while True:
try:
data = stream.read(4000)
if len(data) == 0:
break
buffer += data
while len(buffer) > 4000:
if recognizer.AcceptWaveform(buffer[:4000]):
result = recognizer.Result()
try:
text = json.loads(result)["text"]
print(f"你说: {text}")
return text
except 网页链接 as e:
print(f"JSON解析错误: {str(e)}")
buffer = buffer[4000:]
except Exception as e:
print(f"语音识别错误: {str(e)}")
while buffer:
if len(buffer) > 4000:
if recognizer.AcceptWaveform(buffer[:4000]):
result = recognizer.Result()
try:
text = json.loads(result)["text"]
print(f"你说: {text}")
return text
except 网页链接 as e:
print(f"JSON解析错误: {str(e)}")
buffer = buffer[4000:]
else:
if recognizer.AcceptWaveform(buffer):
result = recognizer.FinalResult()

