
python吧 关注:470,983贴子:1,956,917
- 11回复贴,共1页
 人
人
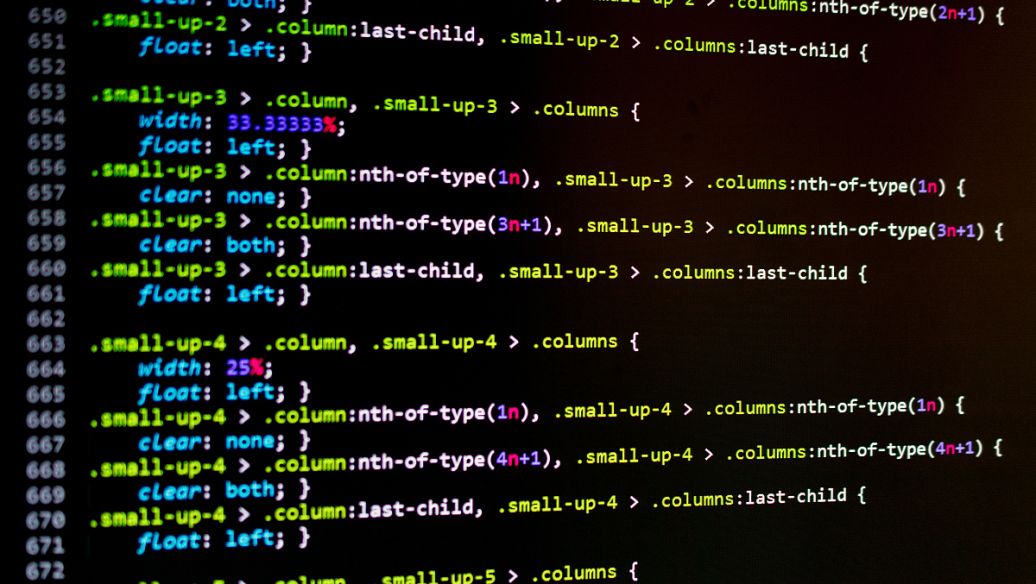


# coding=utf-8
import time
import re
import os
import sys
import codecs
import shutil
import numpy as np
import matplotlib
import scipy
import matplotlib.pyplot as plt
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import HashingVectorizer if __name__ == "__main__": #########################################################################
# 第一步 计算TFIDF
# 文档预料 空格连接
corpus = []
# 读取预料 一行预料为一个文档
for line in open('C-class-fenci.txt', 'r', encoding='utf-8').readlines():
corpus.append(line.strip())
# 将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer()
# 该类会统计每个词语的tf-idf权值
transformer = TfidfTransformer()
# 第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
# 获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
# 将tf-idf矩阵抽取出来 元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf.toarray()
# 打印特征向量文本内容
print('Features length: ' + str(len(word)))
"""
# 输出单词
for j in range(len(word)):
print(word[j] + ' ')
# 打印每类文本的tf-idf词语权重 第一个for遍历所有文本 第二个for便利某一类文本下的词语权重
for i in range(len(weight)):
print u"-------这里输出第", i, u"类文本的词语tf-idf权重------"
for j in range(len(word)):
print weight[i][j],
""" ########################################################################
# 第二步 聚类Kmeans
print('Start Kmeans:')
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=2)
print(clf)
pre = clf.fit_predict(weight)
print(pre) #中心点
print(clf.cluster_centers_)
print(clf.inertia_)
########################################################################
# 第三步 图形输出 降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #输出两维
newData = pca.fit_transform(weight) #载入N维
print(newData)
x = [n[0] for n in newData]
y = [n[1] for n in newData]
plt.scatter(x, y, c=pre, s=100)
plt.legend()
plt.title("Cluster with Text Mining")
plt.show()
import time
import re
import os
import sys
import codecs
import shutil
import numpy as np
import matplotlib
import scipy
import matplotlib.pyplot as plt
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import HashingVectorizer if __name__ == "__main__": #########################################################################
# 第一步 计算TFIDF
# 文档预料 空格连接
corpus = []
# 读取预料 一行预料为一个文档
for line in open('C-class-fenci.txt', 'r', encoding='utf-8').readlines():
corpus.append(line.strip())
# 将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer()
# 该类会统计每个词语的tf-idf权值
transformer = TfidfTransformer()
# 第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
# 获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
# 将tf-idf矩阵抽取出来 元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf.toarray()
# 打印特征向量文本内容
print('Features length: ' + str(len(word)))
"""
# 输出单词
for j in range(len(word)):
print(word[j] + ' ')
# 打印每类文本的tf-idf词语权重 第一个for遍历所有文本 第二个for便利某一类文本下的词语权重
for i in range(len(weight)):
print u"-------这里输出第", i, u"类文本的词语tf-idf权重------"
for j in range(len(word)):
print weight[i][j],
""" ########################################################################
# 第二步 聚类Kmeans
print('Start Kmeans:')
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=2)
print(clf)
pre = clf.fit_predict(weight)
print(pre) #中心点
print(clf.cluster_centers_)
print(clf.inertia_)
########################################################################
# 第三步 图形输出 降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #输出两维
newData = pca.fit_transform(weight) #载入N维
print(newData)
x = [n[0] for n in newData]
y = [n[1] for n in newData]
plt.scatter(x, y, c=pre, s=100)
plt.legend()
plt.title("Cluster with Text Mining")
plt.show()
